搜Mp3
?intitle:index.of? mp3 歌手名
搜动画
?intitle:index.of? swf
其他类推
"parent directory " /appz/ -xxx -html -htm -php -shtml -opendivx -md5 -md5sums
"parent directory " DVDRip -xxx -html -htm -php -shtml -opendivx -md5 -md5sums
"parent directory "Xvid -xxx -html -htm -php -shtml -opendivx -md5 -md5sums
"parent directory " Gamez -xxx -html -htm -php -shtml -opendivx -md5 -md5sums
"parent directory " MP3 -xxx -html -htm -php -shtml -opendivx -md5 -md5sums
"parent directory " Name of Singer or album -xxx -html -htm -php -shtml -opendivx -md5 -md5sums
Notice that i am only changing the word after the parent directory, change it to what you want and you will get a lot of stuff.
2009年4月29日星期三
mess with the best,die like the rest
据说是美国海军陆战队的口号.
mess with -- 干涉
the best -- (自称)
mess with the best -- 敢与老子作对
die like the rest -- 死无葬身之地(跟他们一样下场)
完整的全文应该是: If you mess with the best, you will die like the rest.
//以上解释, 不敢肯定. 最好有上下文, 或者请教权威出处.
其他翻译有:
与强者同行,无惧生死。
要做事,就找最优秀的一起干;要死,也一定要选择从容的离开。
跟我叫板,你死定了。
顺我者昌,逆我者亡。
尚无法确定真确的意思和用法.
mess with -- 干涉
the best -- (自称)
mess with the best -- 敢与老子作对
die like the rest -- 死无葬身之地(跟他们一样下场)
完整的全文应该是: If you mess with the best, you will die like the rest.
//以上解释, 不敢肯定. 最好有上下文, 或者请教权威出处.
其他翻译有:
与强者同行,无惧生死。
要做事,就找最优秀的一起干;要死,也一定要选择从容的离开。
跟我叫板,你死定了。
顺我者昌,逆我者亡。
尚无法确定真确的意思和用法.
2009年4月27日星期一
修改默认的HTTP Response Header
黑客通常通过获取一个HTTP Response,然后解析出HTTP Response Header来知道对方用的是什么web 服务器软件,如下:
对于Tomcat,Header一般会暴露如下信息:
Server: Apache-Coyote/1.1
修改是在conf/server.xml,在Connector 元素中设置server属性即可。如下:
对于apache呢?
只要在httpd.conf中配上如下两个参数:
对于IIS来说有一个工具(URLScan)可以用来修改这个HTTP Response Header,让黑客得到假的Header信息,URLScan的地址:http://learn.iis.net/page.aspx/473/using-urlscanHTTP/1.1 200 OK
Server: Microsoft-IIS/5.0
Date: Thu, 07 Jul 2005 13:08:16 GMT
Content-Length: 1270
对于Tomcat,Header一般会暴露如下信息:
Server: Apache-Coyote/1.1
修改是在conf/server.xml,在Connector 元素中设置server属性即可。如下:
对于apache呢?
只要在httpd.conf中配上如下两个参数:
ServerSignature Off
ServerTokens Prod
2009年4月26日星期日
Go figure
Example 1:Ironically, when asked about improvement, both parties indicated
that they thought communication should be more intense. Go figure!
Example 2: The prepositions are strangely the last thing almost all the children learn in a language. Go figure!
Example 3: Women and children are the first targets of war. Go figure.
Example 4: Go figure: Weight loss is one of the worst reasons for exercise.
Now, if your definitions of "go figure" run along the lines of "wow, isn't that right?" or "who'd have thought?" or "how come", they're all correct.
Think of "go figure" as short for "go and figure it out for yourself". It is used more like an exclamation, though, punctuating an unexpected fact. Oh yeah, that's right.
2009年4月25日星期六
大事记-中国海军60周年最大规模海上阅兵
2009年4月23日,一场展示各国海军共同构建和谐海洋决心的海上大阅兵,在青岛附近的黄海海域展开。这是中国第一次举办多国海军检阅活动,也是中国海军历史上最大规模的海上阅兵,来自14个国家的21艘舰艇同时接受检阅。胡锦涛主席亲临检阅。
14时20分,《分列式进行曲》的激昂旋律在“石家庄”号阅兵舰上响起。阅兵舰舰艏左前方,由25艘潜艇、驱逐舰、护卫舰和导弹快艇组成的中国海军受阅舰艇编队劈波而来。
首先接受检阅的是“长征6”号核动力潜艇。在它的带领下,曾创造潜行时间最长世界纪录的“长征3”号核动力潜艇和“长城218”号、“长城177”号常规动力潜艇以水面航行状态逐一通过阅兵舰。
新华社
海上阅兵原定上午9:00开始,并且由CCTV直播,但是忽然推迟到下午2:00开始,直播也被取消,上午胡主席进行了会见29国海军代表团团长活动。

4月23日上午,国家主席、中央军委主席胡锦涛在青岛会见应邀前来参加中国人民解放军海军成立60周年庆典活动的29国海军代表团团长,代表中国政府和军队向参加庆典活动的各国海军官兵表示热烈欢迎。 新华社记者王建民摄

4月23日下午,中共中央总书记、国家主席、中央军委主席胡锦涛在青岛出席庆祝人民海军成立60周年海上阅兵活动。这是胡锦涛主席热情地向受阅舰艇官兵挥手致意。新华社记者王建民摄

4月24日晚,在庆祝中国人民解放军海军成立60周年之际,中共中央总书记、国家主席、中央军委主席胡锦涛在北京亲切会见海军老同志和英模代表。这是胡锦涛和战斗英雄麦贤得亲切握手交谈。新华社记者 查春明 摄

throw on相关词组和用法
throw on
v.匆匆穿上
eg: You jump out of bed, throw on a baseball cap and some clothes, and rush down to your workplace.
throw on the defensive (迫使采取守势)
throw one's bread upon the waters (v. 行善)
throw one's hat in the ring ( v. 宣布加入战斗)
throw one's sword into the scale (v. 用武力解决)
throw one's weight about (v. 仗势欺人)
throw oneself on (v.依赖)
throw oneself upon the country (要求陪审团审判)
throw oneself at (v.向...猛扑过去, 拼命讨好)
v.匆匆穿上
eg: You jump out of bed, throw on a baseball cap and some clothes, and rush down to your workplace.
throw on the defensive (迫使采取守势)
throw one's bread upon the waters (v. 行善)
throw one's hat in the ring ( v. 宣布加入战斗)
throw one's sword into the scale (v. 用武力解决)
throw one's weight about (v. 仗势欺人)
throw oneself on (v.依赖)
throw oneself upon the country (要求陪审团审判)
throw oneself at (v.向...猛扑过去, 拼命讨好)
2009年4月22日星期三
甲骨文74亿美元收购Sun
甲骨文周一(09-4-20)宣布,将以每股9.5美元的价格收购Sun,这一价格比Sun上周五收盘价高出了42%。包括Sun的现金和债务在内,该交易的价值为74亿美元。
如果此次交易顺利达成,则Sun将成为甲骨文自2005年1月以来的第52个收购对象。其中最大的几次并购分别是:2005年初,甲骨文以103亿美元收购全球第二大客户关系管理软件厂家仁科(PeopleSoft);2007年以33亿美元收购商业情报软件厂家海波龙(Hyperion);2008年初,以85亿美元收购中间件巨头BEA。
如果此次交易顺利达成,则Sun将成为甲骨文自2005年1月以来的第52个收购对象。其中最大的几次并购分别是:2005年初,甲骨文以103亿美元收购全球第二大客户关系管理软件厂家仁科(PeopleSoft);2007年以33亿美元收购商业情报软件厂家海波龙(Hyperion);2008年初,以85亿美元收购中间件巨头BEA。
而甲骨文的收入也迅速膨胀。2004财年甲骨文总收入102亿美元,实现净利润27亿美元,2008财年总收入224亿美元,实现净利润55亿美元。
Sun今年1月份发布第二财季财报时表示,软件业务营收增长了21%,增幅似乎不小,但软件业务年营收仅为6亿美元。分析师预计今年Sun营收将达到124亿美元。Sun从本质上来说是一家硬件公司,这也是分析师预计其本财年将会亏损的原因。Sun各项业务并入甲骨文后,甲骨文将有能力向全球企业用户提供包括硬件、软件和技术支持在内的一店式整体解决方案。
立此存照。Lenny中用LVM调整磁盘卷大小
最近报/root分区磁盘不足,有幸是在安装系统时采用了LVM,否则问题就难解决了。
最初的分区:
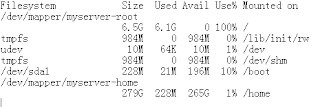
现在要压缩myserver-home ,增加myserver-root。
查看物理卷
#pvdisplay
略……
查看卷组
#vgdisplay
略……
查看逻辑卷
#lvdisplay
确定要变更的两个逻辑卷名:
/dev/myserver/home 挂载点是 /home
/dev/myserver/root 挂载点是 /
(一)减少/dev/myserver/home
#umount /home
#mke2fs -n /dev/myserver/home
执行这个命令是要计算调整块的最终大小。我要将/dev/myserver/home减少到50G,而将腾出的空间给/dev/myserver/root.
上面的数据显示,每块大小为4096Bytes ,总共有74249216块。
50G=53687091200 Bytes =13107200 blocks
减少的块数=74249216 - 13107200=61142016
减少的61142016块= 238836M
#resize2fs -f /dev/myserver/home 13107200
#lvreduce -L-238836M /dev/myserver/home
#mount /home
检查是否减少了
#df -lh
(二)扩展/dev/myserver/root 的大小
#lvextend -L+238836M /dev/myserver/root
注意,这里在其他某些linux系统本可以执行ext2online 来实现,但是Lenny中没有这个命令,本应该用
#resize2fs /dev/myserver/root
检查是否增加了
#df -lh
完毕!
参考:
http://www.ownlinux.cn/2009/03/26/debian-linux-lvm/
lvm(逻辑卷管理器)的介绍和常用功能流程实验
LVM使用手册
最初的分区:

现在要压缩myserver-home ,增加myserver-root。
查看物理卷
#pvdisplay
略……
查看卷组
#vgdisplay
略……
查看逻辑卷
#lvdisplay
--- Logical volume ---
LV Name /dev/myserver/root
VG Name myserver
LV UUID g8bztp-lrp3-XGhk-O6PB-ctZn-Yl5M-Dr247z
LV Write Access read/write
LV Status available
# open 1
LV Size 6.52 GB
Current LE 1668
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 254:0
--- Logical volume ---
LV Name /dev/myserver/swap_1
VG Name myserver
LV UUID fsoPym-loXw-NfQW-3Uff-jMtM-1N1q-NGwSIr
LV Write Access read/write
LV Status available
# open 1
LV Size 5.63 GB
Current LE 1441
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 254:1
--- Logical volume ---
LV Name /dev/myserver/home
VG Name myserver
LV UUID 2fdbfk-sc9H-bKHn-Po5s-8q38-67Di-lFKZXz
LV Write Access read/write
LV Status available
# open 1
LV Size 293.00 GB
Current LE 12800
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 254:2
确定要变更的两个逻辑卷名:
/dev/myserver/home 挂载点是 /home
/dev/myserver/root 挂载点是 /
(一)减少/dev/myserver/home
#umount /home
#mke2fs -n /dev/myserver/home
mke2fs 1.41.3 (12-Oct-2008)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
18563072 inodes, 74249216 blocks
3712460 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=4294967296
2266 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872, 71663616
执行这个命令是要计算调整块的最终大小。我要将/dev/myserver/home减少到50G,而将腾出的空间给/dev/myserver/root.
上面的数据显示,每块大小为4096Bytes ,总共有74249216块。
50G=53687091200 Bytes =13107200 blocks
减少的块数=74249216 - 13107200=61142016
减少的61142016块= 238836M
#resize2fs -f /dev/myserver/home 13107200
#lvreduce -L-238836M /dev/myserver/home
#mount /home
检查是否减少了
#df -lh
(二)扩展/dev/myserver/root 的大小
#lvextend -L+238836M /dev/myserver/root
注意,这里在其他某些linux系统本可以执行ext2online 来实现,但是Lenny中没有这个命令,本应该用
# umount /dev/myserver/root但是因为 /dev/myserver/root在使用中,无法执行umount ,所以直接执行如下命令即可:
# resize2fs /dev/myserver/root
# mount /dev/myserver/root /
#resize2fs /dev/myserver/root
检查是否增加了
#df -lh
完毕!
参考:
http://www.ownlinux.cn/2009/03/26/debian-linux-lvm/
lvm(逻辑卷管理器)的介绍和常用功能流程实验
LVM使用手册
2009年4月20日星期一
Locard's Exchange Principle
On a live system, changes will occur simply due to the passage of time, as processes work, as data is saved and deleted, as network connections time out or are created, and so on. Some changes happen when the system just sits there and runs. Changes also occur as the investigator
runs programs on the system to collect information, volatile or otherwise. Running a program causes information to be loaded into physical memory, and in doing so, physical memory used by other, already running processes may be written to the page file. As the investigator collects information and sends it off the system, new network connections will be created. All these changes can be collectively explained by Locard’s Exchange Principle.
In the early 20th century, Dr. Edmond Locard’s work in the area of forensic science
and crime scene reconstruction became known as Locard’s Exchange Principle.
This principle states, in essence, that when two objects come into contact, material is
exchanged or transferred between them. If you watch the popular CSI crime show
on TV, you’ll invariably hear one of the crime scene investigators refer to possible
transfer.This usually occurs after a car hits something or when an investigator examines
a body and locates material that seems out of place.
Edmond Locard (1877–1966) studied law at the Institute of Legal Medicine and worked subsequently as an assistant to the forensic pioneer Alexandre Lacassagne prior to directing the forensic laboratory in Lyon, France. Locard's techniques proved useful to the French Secret Service during World War I (1914–1918), when Locard was able to determine where soldiers and prisoners had died by examining the stains on their uniforms.
Like Hans Gross and Alphonse Bertillon before him, Locard advocated the application of scientific methods and logic to criminal investigation and identification. Locard's work formed the basis for what is widely regarded as a cornerstone of the forensic sciences, Locard's Exchange Principle, which states that with contact between two items, there will be an exchange. It was Locard's assertion that when any person comes into contact with an object or another person, a cross-transfer of physical evidence occurs. By recognizing, documenting, and examining the nature and extent of this evidentiary exchange, Locard observed that criminals could be associated with particular locations, items of evidence, and victims. The detection of the exchanged materials is interpreted to mean that the two objects were in contact. This is the cause and effect principle reversed; the effect is observed and the cause is concluded.
Crime reconstruction involves examining the available physical evidence, those materials left at or removed from the scene, victim, or offender, for example hairs, fibers, and soil, as well as fingerprints, footprints, genetic markers (DNA), or handwriting. These forensically established contacts are then considered in light of available and reliable witness, the victim, and a suspect's statements. From this, theories regarding the circumstances of the crime can be generated and falsified by logically applying the information of the established facts of the case.
Locard's publications make no mention of an "exchange principle," although he did make the observation "Il est impossible au malfaiteur d'agir avec l'intensité que suppose l'action criminelle sans laisser des traces de son passage." (It is impossible for a criminal to act, especially considering the intensity of a crime, without leaving traces of this presence.). The term "principle of exchange" first appears in Police and Crime-Detection, in 1940, and was adapted from Locard's observations.
source:http://www.enotes.com/forensic-science/locard-s-exchange-principle
2009年4月19日星期日
排列组合
分 类 计 数 原 理
做一件事,完成它有n类不同的办法。第一类办法中有m1种方法,第二类办法中有m2种方法……,第n类办法中有mn种方法,则完成这件事共有:N=m1+m2+…+mn种方法。
分 步 计 数 原理
做一件事,完成它需要分成n个步骤。第一步中有m1种方法,第二步中有m2种方法……,第n步中有mn种方法,则完成这件事共有:N=m1 m2 … mn种方法。
处理实际问题时,要善于区分是用分类计数原理还是分步计数原理,这两个原理的标志是“分类”还是“分步骤”。
排列 :从n个不同的元素中取m(m≤n)个元素,按照一定的顺序排成一排,叫做从n个不同的元素中取m个元素的排列。
组合:从n个不同的元素中,任取m(m≤n)个元素并成一组,叫做从n个不同的元素中取m个元素的组合。
排列数:从n个不同的元素中取m(m≤n)个元素的所有排列的个数,叫做从n个不同元素中取出m个元素的排列数,记为Pnm
组合数:从n个不同的元素中取m(m≤n)个元素的所有组合的个数,叫做从n个不同元素中取出m个元素的组合数,记为Cnm
选排列数

全排列数

组合公式:

二项式定理:

(1)项数:n+1项
(2)指数:各项中的a的指数由n起依次减少1,直至0为止;b的指数从0起依次增加1,直至n为止。而每项中a与b的指数之和均等于n 。
(3)二项式系数:二项式系数具有对称性,与两端等离的两项的二项式系数相等。
二项展开式的性质

做一件事,完成它有n类不同的办法。第一类办法中有m1种方法,第二类办法中有m2种方法……,第n类办法中有mn种方法,则完成这件事共有:N=m1+m2+…+mn种方法。
分 步 计 数 原理
做一件事,完成它需要分成n个步骤。第一步中有m1种方法,第二步中有m2种方法……,第n步中有mn种方法,则完成这件事共有:N=m1 m2 … mn种方法。
处理实际问题时,要善于区分是用分类计数原理还是分步计数原理,这两个原理的标志是“分类”还是“分步骤”。
排列 :从n个不同的元素中取m(m≤n)个元素,按照一定的顺序排成一排,叫做从n个不同的元素中取m个元素的排列。
组合:从n个不同的元素中,任取m(m≤n)个元素并成一组,叫做从n个不同的元素中取m个元素的组合。
排列数:从n个不同的元素中取m(m≤n)个元素的所有排列的个数,叫做从n个不同元素中取出m个元素的排列数,记为Pnm
组合数:从n个不同的元素中取m(m≤n)个元素的所有组合的个数,叫做从n个不同元素中取出m个元素的组合数,记为Cnm
选排列数
全排列数
组合公式:
二项式定理:
(1)项数:n+1项
(2)指数:各项中的a的指数由n起依次减少1,直至0为止;b的指数从0起依次增加1,直至n为止。而每项中a与b的指数之和均等于n 。
(3)二项式系数:二项式系数具有对称性,与两端等离的两项的二项式系数相等。
二项展开式的性质

Ubuntu8安装统计软件R
1. 在 /etc/apt/sources.list 中添加:
deb http://mirrors.geoexpat.com/cran/bin/linux/ubuntu intrepid/
其他镜像地址列表:http://mirrors.geoexpat.com/cran/
2.安装
sudo apt-get update
sudo apt-get install r-base
3.如果想从源码编译安装,则需要r-base-dev
sudo apt-get install r-base-dev
更多信息:http://www.r-project.org/
deb http://mirrors.geoexpat.com/cran/bin/linux/ubuntu intrepid/
其他镜像地址列表:http://mirrors.geoexpat.com/cran/
2.安装
sudo apt-get update
sudo apt-get install r-base
3.如果想从源码编译安装,则需要r-base-dev
sudo apt-get install r-base-dev
更多信息:http://www.r-project.org/
Open Source ETL (Extraction, Transform, Load) Written in Java[收藏]
- Octopus
 - Octopus is a simple Java-based Extraction, Transform, and Loading (ETL) tool. It may connect to any JDBC data sources and perform transformations defined in an XML file. A loadjob-generator is provided to generate Octopus loadjob skeletons from an existing database. Many different types of databases can be mixed (MSSQL, Oracle, DB2, QED, JDBC-ODBC with Excel and Access, MySQL, CSV-files, XML-files,...) Three special JDBC drivers come with Octopus to support JDBC access to CSV-files (CSV-JDBC), MS-SQL (FreeTDS) and XML. Octopus supports Ant and JUnit to create a database / tables and extract/load data during a build or test process.
- Octopus is a simple Java-based Extraction, Transform, and Loading (ETL) tool. It may connect to any JDBC data sources and perform transformations defined in an XML file. A loadjob-generator is provided to generate Octopus loadjob skeletons from an existing database. Many different types of databases can be mixed (MSSQL, Oracle, DB2, QED, JDBC-ODBC with Excel and Access, MySQL, CSV-files, XML-files,...) Three special JDBC drivers come with Octopus to support JDBC access to CSV-files (CSV-JDBC), MS-SQL (FreeTDS) and XML. Octopus supports Ant and JUnit to create a database / tables and extract/load data during a build or test process. - Xineo - Xineo XIL (XML Import Langage) defines an XML language for transforming various record-based data sources into XML documents, and provides a fully functional XIL processing implementation. This implementation has built-in support for relational (via JDBC) and structured text (like CSV) sources, and is extensible thanks to its public API, allowing dynamic integration of new data source implementations. It also provides an abstraction over output format, and the Xineo implementation can generate output documents into stream or as DOM document. Xineo's implementation built-in data sources include : Relational data via JDBC and Structured text via regular expressions.
- CloverETL - CloverETL Features include internally represents all characters as 16bit, converts from most common character sets (ASCII, UTF-8, ISO-8859-1,ISO-8859-2, etc), works with delimited or fix-length data records, data records (fields) are internally handled as a variable-length data structures, fields can have default values, handles NULL values, cooperates with any database with JDBC driver, transforming of the data is performed by independent components, each running as an independent thread, framework implements so called pipeline-parallelism, metadata describing structure of data files (records) can be read from XML and transformation graphs can be read from XML
- BabelDoc - BabelDoc is a Java framework for processing documents in linear stages, it tracks documents and can reintroduce documents back into into the pipelines, it is monitorable and configurable through a number of interfaces, it can be run standalone, in server processes or in application servers, it can be reconfigured dynamically by text files and database tables.
- Joost - Java implementation of the Streaming Transformations for XML (STX) language. Streaming Transformations for XML (STX) is a one-pass transformation language for XML documents. STX is intended as a high-speed, low memory consumption alternative to XSLT. Since it does not require the construction of an in-memory tree, it is suitable for use in resource constrained scenarios.
- CB2XML - CB2XML (CopyBook to XML) is a COBOL CopyBook to XML converter written in Java and based on the SableCC parser generator. This project includes utilities to convert an XML instance file into its COBOL copybook equivalent string buffer and vice versa. You can find additional information about supporting Jurasic systems here.
- mec-eagle - JAVA XML XSL B2B integration software:SWING based GUI,an EDI to XML, XML to XML and XML to EDI converter,client-server architecture.All EDI standards are supported:EDIFACT,ANSI X.12,SAP IDOC,XCBL,RosettaNet,Biztalk.Included comm:SMTP,FTP,HTTP(S),PGP/MIME
- Transmorpher - Transmorpher is an environment for processing generic transformations on XML documents. It aims at complementing XSLT in order to:
- describe easily simple transformations (removing elements, replacing tag and attribute names, concatenating documents...);
- allowing regular expression transformations on the content;
- composing transformations by linking their (multiple) output to input;
- iterating transformations, sometimes until saturation (closure operation);
- integrating external transformations.
- XPipe - XPipe is an approach to manageable, scaleable, robust XML processing based on the assembly line principle, common in many areas of manufacturing. XPipe as being an attempt to take what was great about the original Unix pipe idea and apply it for structured information streams based on XML.
- DataSift - DataSift is a powerful java data validation and transformation framework, aimed at enterprise software development, which provides developers with an extensible architecture they can fully adapt. Almost every feature in it can be configured and extended in some way.
- Xephyrus Flume - Flume is a component pipeline engine. It allows you to chain together multiple workers into a pipeline mechanism. The intention of Flume is that each of the workers would provide access to a different type of technology. For example, a pipeline could consist of a Jython script worker followed by a BeanShell script worker followed by an XSLT worker.
- Smallx - Smallx supports streaming of XML infosets to allow processing of very large documents (500MB-1GB). Processing is specified in an XML syntax that describes an XML pipeline--which is a sequence of components that consume and produce infosets. This allows chaining of XML component standards like XSLT. Also, there is a full component API that allows developers to easily write their own components.
- Nux - Nux is a toolkit making efficient and powerful XML processing easy. It is geared towards embedded use in high-throughput XML messaging middleware such as large-scale Peer-to-Peer infrastructures, message queues, publish-subscribe and matchmaking systems for Blogs/newsfeeds, text chat, data acquisition and distribution systems, application level routers, firewalls, classifiers, etc. Nux reliably processes whatever data fits into main memory (even, say, 250 MB messages), but it is not an XML database system, and does not attempt to be one. Nux integrates best-of-breed components, containing extensions of the XOM, Saxon and Lucene open-source libraries.
- KETL - KETL is an extract, transform, and load (ETL) tool designed by Kinetic Networks. KETL includes job scheduling and alerting capabilities. The KETL Server is a Java-based data integration platform consisting of a multi-threaded server that manages various job executors. Jobs are defined using an XML definition language.
- Kettle - K.E.T.T.L.E (Kettle ETTL Environment) is a meta-data driven ETTL tool. (ETTL: Extraction, Transformation, Transportation & Loading). No code has to be written to perform complex data transformations. Environment means that it is possible to create plugins to do custom transformations or access propriatary data sources. Kettle supports most databases on the market and has native support for slowly chaning dimensions on most platforms. The complete Kettle source code is over 160,000 lines of java code.
- Netflux - Metadata based tool to allow for easier manipulations. Spring based configuration, BSF based scripting support, pluggable JDBC based data sources and sinks. A server and a GUI are planned.
- OpenDigger - OpenDigger is a java based compiler for the xETL language. xETL is a language specifically projected to read, manipulate and write data in any format and database. With OpenDigger/XETL you can build Extraction-Transformation-Loading (ETL) programs virtually from and to any database platform.
- ServingXML - ServingXML is a markup language for expressing XML pipelines, and an extensible Java framework for defining the elements of the language. It defines a vocabulary for expressing flat-XML, XML-flat, flat-flat, and XML-XML transformations in pipelines. ServingXML supports reading content as XML files, flat files, SQL queries or dynamically generated SAX events, transforming it with XSLT stylesheets and custom SAX filters, and writing it as XML, HTML, PDF or mail attachments. ServingXML is suited for converting flat file or database records to XML, with its support for namespaces, variant record types, multi-valued fields, segments and repeating groups, hierarchical grouping of records, and record-by-record validation with XML Schema.
- Talend - Talend Open Studio is full-featured Data Integration OpenSource solution (ETL). Its graphical user interface, based on Eclipse Rich Client Platform (RCP) includes numerous components for business process modelling, as well as technical implementations of extracting, transformation and mapping of data flows. Data related script and underlying programs are generated in Perl and Java code.
- Scriptella - Scriptella is an ETL and script execution tool. Its primary focus is simplicity. It doesn't require the user to learn another complex XML-based language to use it, but allows the use of SQL or another scripting language suitable for the data source to perform required transformations.
- ETL Integrator - ETL (a highly unimaginative name) consists of 3 components. An ETL service engine that is a JBI compliant service engine implementation which can be deployed in a JBI container. An ETL Editor that is a design time netbeans module which allow users to design ETL process in a graphical way. An ETL Project that is a design time netbeans module which allows users to package ETL related artifacts in a jar file which could be deployed onto the ETL service engine.
- Jitterbit - Jitterbit can act as a powerful ETL tool. Operations are defined, configured, and monitored with a GUI. The GUI can create document definitions, from simple flat file structures to complex hierarchic files structures. Jitterbit includes drag-and-drop mapping tool to transform data between your various system interfaces. Furthermore, one can set schedules, create success and failure events and track the results for your integration operations. Jitterbit supports Web Services, XML Files, HTTP/S, FTP, ODBC, Flat and Hierarchic file structures and file shares.
- Apatar - Apatar integrates databases, files and applications. Apatar includes a visual job designer for defining mapping, joins, filtering, data validation and schedules. Connectors include MySQL, PostgreSQL, Oracle, MS SQL, Sybase, FTP, HTTP, SalesForce.com, SugarCRM, Compiere ERP, Goldmine CRM, XML, flat files, Webdav, Buzzsaw, LDAP, Amazon and Flickr. No coding is required to accomplish even a complex integration. All metadata is stored in XML.
- Spring Batch - Spring Batch is a lightweight, comprehensive batch framework designed to enable the development of robust batch applications. Spring Batch provides reusable functions that are essential in processing large volumes of records, including logging/tracing, transaction management, job processing statistics, job restart, skip, and resource management. It also provides more advance technical services and features that will enable extremely high-volume and high performance batch jobs though optimization and partitioning techniques.
- JasperETL - JasperETL was developed through a technology partnership with Talend. JasperETL includes Eclipse based user interfaces for process design, transformation mapping, debugging, process viewing. The project includes over 30 connectors like flat files, xml, databases, email, ftp and more. It includes wizards to help configure the processing of complex file formats including positional, delimited, CSV, RegExp, XML, and LDIF formatted data.
- Pentaho Data Integration - Pentaho Data Integration provides a declarative approach to ETL where you specify what to do rather than how to do it. It includes a transformation library with over 70 mapping objects. In includes data warehousing capability for slowly changing and junk Dimensions. Includes support for multiple data sources including over 25 open source and proprietary database platforms, flat files, Excel documents, and more. The architecture is extensible with a plug-in mehcanism.
- Mural - Mural is an open source community with the purpose of developing an ecosystem of products that solve the problems in Master Data Management (MDM). Projects include: Master Index Studio which provides the supports the creation of a master index through the matching, de-duplication, merging, and cleansing . Data Integrator which provides extract, transform, load capability and a wide variety of data formats. Data Quality which features matching, standardization, profiling,and cleansing capabilities. Data Mashup Data Mashup which provides data mashup capability. Data Migrator which supports the migration of database objects across database instances
- Smooks - Smooks provides a wide range of Data Transforms. Supports many different Source and Result types - XML/CSV/EDI/Java/JSON to XML/CSV/EDI/Java/JSON. It supports binding of Java Object Models from any data source. It is designed to process huge messages in the GByte range.
- Data Pipeline - Data Pipeline provides data conversion, data processing, and data transformation. The toolkit has readers and writers for common file formats (CSV, Excel, Fixed-width, JDBC) along with decorators that can be chained together to process and transform data (filter, remove duplicates, lookups, validation).
2009年4月18日星期六
EDA催生出cloudMQ
EDA和CEP火爆了,竟然有人搞出了个cloudMQ ,支持JMS, AMQP and Web Services 类似 Amazon SQS,炒出了Message Queuing as a Service (MaaS)的概念。
2009年4月17日星期五
Trend Prediction in Network Monitoring Systems[收藏]
Trend Prediction in Network Monitoring Systems
March 4th, 2009 by Tim BassFollowing up on Real-Time Predictive Analytics for Web Servers I thought we should “move up a level” and look at various open network monitoring platforms with trend prediction capabilities.
Our web server management team picked Zabbix to monitor a busy production server and then we started to look into adding predictive analytics afterwards. Alberto recommended we look into The R Project for open source predictive analytics, which was interesting because I was just about to blog on TIBCO’s integration of S-Plus with Spotfire. Then, my research led me to an interesting comparative analysis regarding S, S-Plus and R based on Aberto’s recommendation. (Thanks Alberto!)
Instead of writing on S, S-Plus and R today, I thought it might be good to take a look at potential trend prediction capabilities in network monitoring systems, especially the “open, free ones” under the GPL or similar license. Based on this Wikipedia chart, A short comparison between the most common network monitoring systems, there are 3 out of 40 listed NMS platforms with trend prediction capabilities, GroundWork Community, Osmius and Zenoss. Unfortunately for us, Zabbix does not yet have trend prediction capabilities; however, the Zabbix project leader says he plans to add this functionality “in the future,” which is not very encouraging, since we don’t know what “this future functionality” will be.
Osmius claims to be event-oriented software with a “realistic and practical platform” to apply research and investigative results including AI and event correlation processes. Osmius aims reduce the volume of “final events” to process to identify the root cause of problems, including predicting problems before they occur. Osmius boasts off-line data mining capability with a pattern language to discover event occurrence patterns. We need to look into Osmius more and see if there is any substance to the marketing claims.
Unfortunately, we could not find any concrete trend prediction capabilities in GroundWork, especially in the free and open community version of the software. This makes sense since GroundWork is based on Nagios, and Nagios does not have built-in forecasting and predictive analytics. Also, a preliminary look into Zenoss was not very encouraging, as we could not find solid evidence of predictive analytics and forecasting functionality.
As for next steps, I think we’ll look a bit deeper into a few of these software platforms and see if we can find out exactly what forecasting methods they use, if any, for outage prediction. If anyone has any knowledge or experience in these NSM event processing platforms and their capabilities regarding predictive analytics and outage forecasting, please comment. Thanks!
Also, I still have some blogging to do on TIBCO’s integration of Spotfire and Insightful’s S-Plus, both acquired by TIBCO last year, as I recall. I am interested to see when and how TIBCO integrates off-line analytics (Spotfire, Insightful, S-Plus) with real-time event processing.
2009年4月14日星期二
目前90%的病毒不再自我复制
Kaspersky Lab的高级反病毒研究员Roel Schouwenberg近日在谈到过去5年malware的变化时表示:
1、目前90%的病毒不再自我复制。
1、目前90%的病毒不再自我复制。
Criminals generally don't want to draw any attention from anti-malware companies and/or law enforcement. What also adds to this is that today about 90% of the malware we see is not self-replicating.2、malware数量迅速增长,2007年是前20年之和,2008年是2007年的10倍,目前每天发现的新威胁达4万种。
In 2008 we saw ten times as much malware as in 2007. In 2007 we saw the same amount of malware as in the whole twenty years before that combined. Right now we see up to 40,000 new threats per day, even two years ago that would have been very hard to imagine.3.写malware者向盈利性目的转变
There has also been a shift in how people are writing malware. In 2004 we were already seeing the change from people writing malware for fun to writing malware for profit. These days over 98% of all the malware we see is created with profit in mind. So we're fighting professional cyber criminals rather than teenage kids trying to prove themselves like five years ago.http://www.net-security.org/article.php?id=1219&p=1
2009年4月13日星期一
Debian/Ubuntu Linux Install ntop[转]
Q. How do I track my network usage (network usage monitoring) and protocol wise distribution of traffic under Debian Linux? How do I get a complete picture of network activity?
A. ntop is the best tool to see network usage in a way similar to what top command does for processes i.e. it is network traffic monitoring software. You can see network status, protocol wise distribution of traffic for UDP, TCP, DNS, HTTP and other protocols.
ntop is a hybrid layer 2 / layer 3 network monitor, that is by default it uses the layer 2 Media Access Control (MAC) addresses AND the layer 3 tcp/ip addresses. ntop is capable of associating the two, so that ip and non-ip traffic (e.g. arp, rarp) are combined for a complete picture of network activity.
ntop is a network probe that showsIn interactive mode, it displays the network status on the user's terminal. In Web mode, it acts as a Web server, creating a HTML dump of the network status. It sports a NetFlow/sFlow emitter/collector, a HTTP-based client interface for creating ntop-centric monitoring applications, and RRD for persistently storing traffic statistics.Network Load Statistics
How do I install ntop under Debian / Ubuntu Linux?
Type the following commands, enter:$ sudo apt-get update
$ sudo apt-get install ntop
Set ntop admin user password
Type the following command to set password, enter:# /usr/sbin/ntop -A
OR$ sudo /usr/sbin/ntop -A
Restart ntop service
Type the following command, enter:# /etc/init.d/ntop restart
Verify ntop is working, enter:# netstat -tulpn | grep :3000
ntop by default use 3000 port to display network usage via webbrowser.
How do I view network usage stats?
Type the url:http://localhost:3000/
ORhttp://server-ip:3000/
Further readings:
- man ntop
- ntop configuration files located at /etc/ntop/ directory
- ntop project
来源:http://www.cyberciti.biz/faq/debian-ubuntu-install-ntop-network-traffic-monitoring-software/
2009年4月11日星期六
Ubuntu8.10安装中文输入法
安装中文输入法
apt-get install scim-chinese
在/etc/X11/Xsession.d/里新建一个名叫95xinput的文件,文件内容如下
/usr/bin/scim -d
XMODIFIERS="@im=SCIM"
export XMODIFIERS
export GTK_IM_MODULE=scim
保存文件,确认内容无误后,退出X(建议退出X后运行exit命令重新login一次),再进入X的时候就可以用Ctrl+Space调出SCIM了!
现在还不能在基于GTK的软件中调出SCIM,例如不能在leafpad里使用SCIM。解决办法很简单,只要安装scim-gtk2-immodule就可以了。
apt-get install scim-gtk2-immodule
这个命令会根据依赖关系自动安装 scim-server-socket, scim-frontend-socket, scim-config-socket,如果没有安装scim,也会自动安装。
apt-get install scim-chinese
在/etc/X11/Xsession.d/里新建一个名叫95xinput的文件,文件内容如下
/usr/bin/scim -d
XMODIFIERS="@im=SCIM"
export XMODIFIERS
export GTK_IM_MODULE=scim
保存文件,确认内容无误后,退出X(建议退出X后运行exit命令重新login一次),再进入X的时候就可以用Ctrl+Space调出SCIM了!
现在还不能在基于GTK的软件中调出SCIM,例如不能在leafpad里使用SCIM。解决办法很简单,只要安装scim-gtk2-immodule就可以了。
apt-get install scim-gtk2-immodule
这个命令会根据依赖关系自动安装 scim-server-socket, scim-frontend-socket, scim-config-socket,如果没有安装scim,也会自动安装。
Ubuntu8.10安装JDK1.6,Tomcat5.5,eclipse3.4
安装JDK6
下载jdk-6u4-linux-i586.bin
#chmod +x jdk-6u4-linux-i586.bin
#./jdk-6u11-linux-i586.bin
#輸入yes開始安裝,之后会出现一个jdk1.6.0_11的目录
将jdk1.6.0_11拷贝到 /usr/local/ 下
#mv jdk1.6.0_11 /usr/local/
打开.profile
#vim ~/.profile
将下述语句写在里面
JAVA_HOME=/usr/local/jdk1.6.0_11
JRE_HOME=$JAVA_HOME/jre
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export JAVA_HOME
export PATH
export CLASSPATH
安装Tomcat5.5
下载tomcat 5.5 从http://jakarta.apache.org/site/downloads/
#tar xvfz jakarta-tomcat-5.5.9.tar.gz
将解压的文件夹拷贝到/usr/local/
#gedit ~/.bashrc
添加如下行
export CLASSPATH=/usr/local/tomcat/common/lib/jsp-api.jar:/usr/local/tomcat/common/lib/servlet-api.jar
也可以加在 ~/.profile中。
修改端口在 usr/local/tomcat/conf/server.xml
运行
sh /usr/local/tomcat/bin/startup.sh
停止
sh /usr/local/tomcat/bin/shutdown.sh
参考:http://ubuntuforums.org/showthread.php?p=226828
安装Eclipse3.4
我是从http://www.eclipse.org/downloads/上下载的eclipse-jee-ganymede-SR2-linux-gtk.tar.gz
tar zxvf eclipse-jee-ganymede-SR2-linux-gtk.tar.gz
进入目录双击就可以用了。
下载jdk-6u4-linux-i586.bin
#chmod +x jdk-6u4-linux-i586.bin
#./jdk-6u11-linux-i586.bin
#輸入yes開始安裝,之后会出现一个jdk1.6.0_11的目录
将jdk1.6.0_11拷贝到 /usr/local/ 下
#mv jdk1.6.0_11 /usr/local/
打开.profile
#vim ~/.profile
将下述语句写在里面
JAVA_HOME=/usr/local/jdk1.6.0_11
JRE_HOME=$JAVA_HOME/jre
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export JAVA_HOME
export PATH
export CLASSPATH
安装Tomcat5.5
下载tomcat 5.5 从http://jakarta.apache.org/site/downloads/
#tar xvfz jakarta-tomcat-5.5.9.tar.gz
将解压的文件夹拷贝到/usr/local/
#gedit ~/.bashrc
添加如下行
export CLASSPATH=/usr/local/tomcat/common/lib/jsp-api.jar:/usr/local/tomcat/common/lib/servlet-api.jar
也可以加在 ~/.profile中。
修改端口在 usr/local/tomcat/conf/server.xml
运行
sh /usr/local/tomcat/bin/startup.sh
停止
sh /usr/local/tomcat/bin/shutdown.sh
参考:http://ubuntuforums.org/showthread.php?p=226828
安装Eclipse3.4
我是从http://www.eclipse.org/downloads/上下载的eclipse-jee-ganymede-SR2-linux-gtk.tar.gz
tar zxvf eclipse-jee-ganymede-SR2-linux-gtk.tar.gz
进入目录双击就可以用了。
Ubuntu8.10中Eclipse SVN插件的unable to load default svn client问题
在Ubuntu8.10 Desktop,Eclipse 3.4,JDK1.6 的环境下,在Eclipse中按照下列地址安装的SVN:
http://subclipse.tigris.org/update_1.4.x
会报错“unable to load default svn client”,
解决办法:
将下面两行添加到 /usr/lib/eclipse/eclipse.ini 文件的 "-vmargs"下面
-Djava.library.path=/usr/share/java/
-Djava.library.path=/usr/lib/jni/
另外最关键的是在安装时必须选择安装SVNKit,不装这个就会报错。
http://subclipse.tigris.org/update_1.4.x
会报错“unable to load default svn client”,
解决办法:
将下面两行添加到 /usr/lib/eclipse/eclipse.ini 文件的 "-vmargs"下面
-Djava.library.path=/usr/share/java/
-Djava.library.path=/usr/lib/jni/
另外最关键的是在安装时必须选择安装SVNKit,不装这个就会报错。
vista中不能创建的目录
偶然发现在vista操作系统中,不能创建名为aux的目录。将此事作为bug向微软社区一提,
答复如下:
这个并不是BUG,而是VISTA中新的命名规则也就是说该名字无法作为文件夹名,这类的词语还包括con, aux, com1, com2, com3, com4, lpt1, lpt2, lpt3, prn 和 nul都是,主要是为了防止系统识别混淆。XP和SERVER中也是一样。
我认为像con,aux这种名字用做文件夹名是很平常的事,Vista为什么要有如此不合情理的规则? 看来,至少在设计的合理性方面,windows和linux相比不止逊色一点点。不禁让人反思,为什么那么多人好端端的linux不用,而要花那么多钱买正版的vista,图个啥?
有人提出可以用如下方式创建和删除:
mkdir c:\aux\\
rmdir c:\aux\\
的确是可以创建和删除aux文件夹,但是这个文件夹创建后无法在里面创建文件,所以只是一种治标不治本的办法。
答复如下:
这个并不是BUG,而是VISTA中新的命名规则也就是说该名字无法作为文件夹名,这类的词语还包括con, aux, com1, com2, com3, com4, lpt1, lpt2, lpt3, prn 和 nul都是,主要是为了防止系统识别混淆。XP和SERVER中也是一样。
我认为像con,aux这种名字用做文件夹名是很平常的事,Vista为什么要有如此不合情理的规则? 看来,至少在设计的合理性方面,windows和linux相比不止逊色一点点。不禁让人反思,为什么那么多人好端端的linux不用,而要花那么多钱买正版的vista,图个啥?
有人提出可以用如下方式创建和删除:
mkdir c:\aux\\
rmdir c:\aux\\
的确是可以创建和删除aux文件夹,但是这个文件夹创建后无法在里面创建文件,所以只是一种治标不治本的办法。
2009年4月10日星期五
osmius安装试用
osmius是一个功能强大的开源分布式监控软件,用C++和JAVA实现。缺点是复杂,文档很少。
特性:
下载安装
1.- Download from http://sourceforge.net/projects/osmius:
osmius_server_linux32_installer_X.YY.ZZ.bin
prompt > chmod 755 osmius_server_linux32_installer_X.YY.ZZ.bin
prompt > ./osmius_server_linux32_installer_X.YY.ZZ.bin
2.- Follow the instructions.
3.- Using FireFox 2.X or 3.X
http://:/osmius
user : root
password: osmius
4.- To start/stop everything (mysql, tomcat and osmius processes)
/ctlXXXXX.sh start
/ctlXXXXX.sh stop
源码获取:
svn co https://osmius.svn.sourceforge.net/svnroot/osmius osmius
http://www.osmius.net
特性:
- Open Source : Osmius exhibits its quality difference.
- Open Analysis : Access to documentation generated during the Analysis Phases as well as articles, architectural diagrams,...
- Osmius leverages ACE : Reusability applied with this extraordinary framework with decades of knowledge and very robust code.
- Multi-Platform : Hardware and operative system independence.
- Architecture Oriented : Osmius is a solution to a set of systems and problems, it is not just a product.
- Market Oriented : Osmius has a Business Plan and an Open Source Business Model with Peopleware.es
| Operative Systems: Osmius Central Server | Linux : Solaris : Windows (coming soon) |
| Operative Systems: Master Agents | Windows : Linux : HP-UX : Solaris |
| Used Frameworks: Engine | C++ → ADAPTIVE Communication Environment : MPC |
| Used Frameworks: Java Console | Java → J2EE : Spring : Hibernate : |
| Database | MySql 5.X initially |
| Web Server | TomCat 5.25.X |
| Reporting | JasperReports |
| Dataware House | Included |
| Integrations | OpenView - Nagios - Scripts - SMS - email - etc |
| New agent development Framework | Osmius Framework : 1 agent per week |
| Intrusive Agents | Yes : Mainly OSs and log files |
| NON-Intrusive Agents | Yes : SNMP, Oracle, HTTP, IP services, MySql, Asterisk, VMWare, etc |
| Web client | Firefox 2.X y 3.0.X |
| Licencia | GPL2 |
| ITIL Processes Support | SLA achievement. Availability Management Capacity Planning |
| Benchmarking | + 1000 instances + 1000 services 1500 events per second with 1 CPU 2GHz |
下载安装
1.- Download from http://sourceforge.net/projects/osmius:
osmius_server_linux32_installer_X.YY.ZZ.bin
prompt > chmod 755 osmius_server_linux32_installer_X.YY.ZZ.bin
prompt > ./osmius_server_linux32_installer_X.YY.ZZ.bin
2.- Follow the instructions.
3.- Using FireFox 2.X or 3.X
http://
user : root
password: osmius
4.- To start/stop everything (mysql, tomcat and osmius processes)
源码获取:
svn co https://osmius.svn.sourceforge.net/svnroot/osmius osmius
http://www.osmius.net
2009年4月9日星期四
最近在bbs.secservice.net发了很多帖子
最近在bbs.secservice.net发了很多帖子,主要是关于OSSIM的,JMassLogPro自发布v0.2以后,下一个里程碑的设计还没出来,进展比较缓慢。
Lenny上出现Pango-CRITICAL问题
OSSIM并非SIM而是SEM
lenny使用中的问题
ossim已经有lenny版iso了
更多
Lenny上出现Pango-CRITICAL问题
OSSIM并非SIM而是SEM
lenny使用中的问题
ossim已经有lenny版iso了
更多
订阅:
博文 (Atom)

